Flow based Generative Models 1 : Normalizing Flow
안녕하세요. 굉장히 오랜만에 블로그 포스팅을 재개하게 되었습니다. 한동안 회사랑 학교 생활을 하느라 글을 너무 안 썼습니다. 요즘 Flow based Generative Model 쪽에 굉장히 많은 관심이 생겨서 오랜만의 포스팅은 Flow based Generative model를 공부하고 정리한 시리즈로 구성될 것 같습니다. 참고로 이번 시리즈에서는 다음과 같은 논문들을 기준으로 진행하겠습니다.
- [2014] NICE: NON-LINEAR INDEPENDENT COMPONENTS ESTIMATION
- [2016] DENSITY ESTIMATION USING REAL NVP
- [2018] Glow: Generative Flow with Invertible 1×1 Convolutions
- [2020] Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search
우선, 이번 시간은 Flow based Generative model 가 무엇인지 소개하고 해당 기법을 위해 몇 가지 알아둬야될 기초 지식들을 가볍게 정리해보겠습니다. 참고로 이번 시간의 포스팅은 Lil’Log 블로그 와 박선우님의 블로그 를 많이 참고했기 때문에 겹치는 내용들이 많습니다. (특히 Lil’Log 블로그 글이 굉장히 깔끔하게 정리되어있기 때문에 후반부의 수식전개에서는 저의 약간의 추가 설명 이외엔 거의 번역했다고 보시면 좋을 것 같습니다.)
Generative Models
대부분의 관련 블로그들이 그렇듯 이 글에서도 우선 기존의 생성 모델들이 뭔지 알고 넘어갈 필요가 있습니다. 대표적으로 GAN과 VAE가 있고 이번 시리즈의 메인인 Flow-based generative model 이 있습니다.
- Generative Adversarial Network (GAN) : GAN은 크게 생성자(Generator)와 구분자(Discriminator) 로 나뉘어집니다. 우리가 어떠한 실제 데이터셋을 가지고 있다면, 생성자는 최대한 실제 데이터와 비슷한 데이터를 생성하도록 하는 신경망입니다. 하지만, 결국 생성자가 만든 데이터는 실제 데이터가 아닌 그저 실제와 비슷한 데이터라 가짜 데이터인거죠. 구분자는 그런 가짜 데이터와 실제 데이터 사이에서 진짜와 가짜를 구별하는 신경망입니다. GAN은 이 생성자와 구분자를 경쟁하게 하여 학습시킵니다 (그래서 이름이 “Adversarial”). 생성자는 구분자도 못 알아차릴 만큼 진짜 같은 데이터를 만들고 구분자는 계속해서 가짜를 최대한 구분해내는 것이죠.
- Variational Auto-Encoder (VAE) : 일반적인 Auto-encoder는 고차원 데이터 \(x\) 를 비교적 저차원인 잠재벡터 \(z\)로 압축하고(Encoder) 다시 해당 \(z\)에서 원본 데이터 \(x\)로 복원하도록(Decoder) 합니다. 따라서 보통의 AE들은 잠재벡터 \(z\)에 대한 확률 분포를 데이터셋을 압축 및 복원하면서 구하게 됩니다. VAE는 AE들과는 조금 다릅니다. VAE는 잠재벡터 \(z\)에 대한 확률 분포를 보다 다루기 쉬운 확률 분포 (e.g. Gaussian distribution)에 근사되도록 하여 (결국, 잠재변수\(z\)의 확률 분포는 Gaussian 분포 등을 따른다고 ‘가정’하자는 것이죠), 해당 확률 분포에 따라 만들어진 노이즈를 \(z\)로 삼아 Decoder가 새로운 데이터 \(x\)를 만들 수 있도록 하는 것을 목표로 합니다. 결과적으로, VAE가 잘 학습이 되기만 하면, 우리가 가정한 확률 분포를 기준으로 평균와 편차 등의 파라미터들을 잘 컨트롤한 값을 전달해주면 Decoder가 그럴 듯한 결과물을 만들어주게 됩니다. 이번 시리즈에선 VAE는 다루지 않기 때문에 궁금하신 분들은 굉장히 잘 정리된 이활석님의 오토인코더의 모든 것 영상을 보고 오시는 것을 추천드립니다.
- Flow-based Generative Model : AE와 VAE 를 비롯한 Encoder-Decoder 구조를 갖고 있는 신경망에선 Encoder와 Decoder는 대부분 암시적으로 학습되어집니다. GAN의 Generator와 Discriminator 도 마찬가지죠. 하지만 Flow-based Generative model은 이 둘과는 약간 다릅니다. 결론부터 말씀드리자면 Flow-based generative model은 잠재 벡터 \(z\)의 확률 분포에 대한 일련의 역변환(a sequence of invertible transformations)을 통해 데이터 \(x\)의 분포를 명시적으로 학습하며 이를 간단한게 negative log-likelihood 로 해결합니다. 아마 경험이 있으신 분들은 무엇을 할려는지 바로 알아차리셨겠지만, 그렇지 않으신 분들도 걱정하지 않으셔도 됩니다. 이번 포스팅 시리즈의 주 타켓은 그런 분들을 위한 것이니깐요.
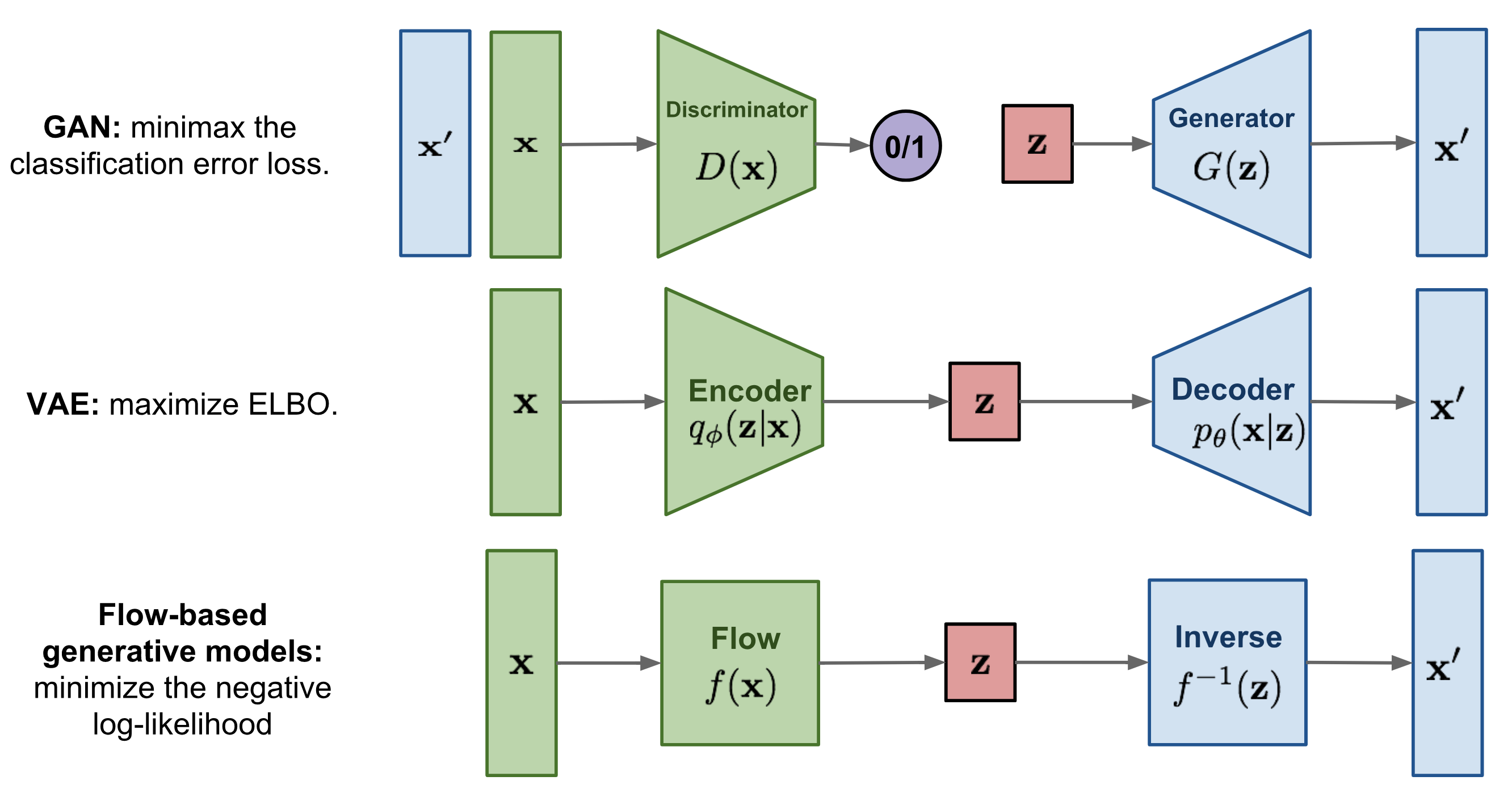
Fig. 1. Comparison of three categories of generative models. (출처 - Lil’Log, Flow-based Deep Generative Models)
Linear Algebra Basics Recap
대부분의 생성모델들은 수학적인 개념들이 많이 나오는데 Flow-based 생성모델도 마찬가집니다. 하지만 기초적인 선형대수 지식으로도 충분히 설명이 가능하기 때문에 이번 절은 기초 선형대수 요약을 제 나름대로의 시나리오로 진행해보겠습니다.(Head는 Lil’Log 가 적은게 너무 적절해서 그냥 그대로…).
일단, 간단한 식을 아래에 적어보겠습니다. \(a\)는 scale, \(b\)는 bias 입니다.
\[y = ax + b = f(x)\]그리고 역함수는 다음과 같이 표현할 수 있습니다.
\[x = (y - b) / a = f^{-1}(y)\]행렬 연산으로도 똑같이 표현해 볼 수 있습니다. (편의상 변수들은 그대로 표기하겠습니다)
\[y = Wx + B = f(x) \\ x = W^{-1}(y -B) = f^{-1}(y)\]이때, \(y=Wx+B\) 처럼 벡터 공간 상에서 선형변환(Linear Transformation) \(Wx\)과 Bias \(B\) 가 더해지는 변환을 Affine Transformation 이라 합니다. 즉, Bias 가 zero 라면 Affine Transformation은 선형성을 만족하게 되지만 그렇지 않다면 비선형 변환입니다. 참고로, 제가 행렬 연산을 예를 들면서 역행렬을 사용했는데 행렬의 경우엔 특정 조건을 만족해야 역행렬을 사용할 수 있습니다. 예시를 위해서 사용했다는 것만 알아두시면 좋을 것 같습니다.
고차원 변수 \(x\) 에 대한 잠재 변수 \(z\) 를 계산하는 신경망이나 반대로 \(z\) 에서 \(x\) 를 계산하는 신경망도 하나의 함수입니다.
\[z = f(x) \\ x =g(z)\]Auto-Encoder 같은 경우엔 \(x = g(f(x))\) 를 만족하도록 학습하는 비지도 학습입니다. VAE는 그 과정에서 \(z\) 의 확률분포가 정규분포 등의 다루기 쉬운 확률분포로 근사되도록 추가적인 수식이 더 적용됩니다. Flow-based 생성모델은 이들과는 조금 다릅니다. Flow-based 생성 모델은 고차원 변수 \(x\) 를 잘 표현할 수 있는 잠재 변수 \(z\) 를 계산하는 \(z = f(x)\) 를 학습하되, \(f\) 의 역함수 \(f^{-1}\) 를 통해서 다시 \(x\) 를 계산하는 것을 목표로합니다. 다음 절에선 이 부분을 좀 더 자세히 설명해보겠습니다.
Change of Variable
수학에서, 어떠한 변수 또는 다변수로 나타낸 식을 다른 변수 또는 다변수로 바꿔 나타내는 것을 변수 변환 (Change of Variable) 라고 합니다 (위키백과 참조) . 다항식으로 예를 들어 보겠습니다.
\[f(x)=x^2-1\]에 변수 변환
\[x = 2t+1\]를 적용하면
\[f(2t+1)=(2t+1)^2 - 1 = 4t^2 + 4t\]가 됩니다. 즉, 변수 \(x\) 로 나타내던 것을 변수 \(t\) 라는 새로운 변수로 나타내게 되었습니다. 사실 이 부분은 누구나 다 알 정도로 간단한 개념입니다. 물론, 이 간단한 개념을 언급하는 이유가 있겠죠?
어떠한 랜덤 변수 \(x\) 와 랜덤 변수 \(x\) 에 대해 각각 다음과 같은 확률 밀도 함수(Probability Density Function, PDF)가 있다고 가정하겠습니다.
\[x \sim p(x) \\ z\sim \pi(z)\]우리가 변수 \(z\) 가 변수 \(x\) 를 잘 표현하는 잠재 변수이고, \(z\) 의 확률 밀도 함수가 주어진다면, 일대일 매핑 함수 \(x=f(z)\) 를 사용해서 새로운 랜덤 변수를 구할 수 있지 않을까 기대할 수 있습니다. 그리고 함수 \(f\)가 가역적(invertible)이라고 가정한다면, 역함수가 존재한다는 의미기 때문에 \(z = f^{-1}(x)\) 도 가능하겠죠? 그럼 우리가 해야 될 것은 알려지지 않은(unknown) \(x\)의 확률 분포 \(p(x)\) 를 구하는 것입니다.
우선 확률 분포의 정의를 적어보겠습니다.
\[\int p(x)dx = \int \pi(z)dz = 1\]확률 밀도 함수의 적분은 당연히 1이 되기 때문에 두 확률밀도 함수의 적분은 동일하게 1이겠죠? 그리고 저희는 \(x = f(z)\) 와 그의 역행렬 \(z=f^{-1}(x)\) 를 알고 있습니다. 그리고 아까 짚고 넘어갔던 변수 변환을 적분식에 적용하면 다음과 같이 표현할 수 있습니다.
\[\int p(x)dx = \int \pi(f^{-1}(x))d f^{-1}(x)\]이것을 한번 더 정리하면 다음과 같이 나타납니다.
\[p(x) = \pi (z)\Bigl|\frac{dz}{dx}\Bigl| = \pi(f^{-1}(x))\Bigl|\frac{df^{-1}}{dx}\Bigl| = \pi(f^{-1}(x))\Bigl|(f^{-1})'(x)\Bigl|\]이렇게 하면, 드디어 우리는 알지 못하는 \(p(x)\) 를 \(z\) 의 확률밀도함수로 표현 할 수 있게 되었습니다. 이 식을 조금 직관적으로 설명하자면 서로 다른 변수 \(x, z\) 의 밀도 함수들 간의 관계는 \(\vert(f^{-1})'(x)\vert\) 만큼의 비율을 갖는다고 볼 수 있습니다. 사실, 우리들은 실제로는 고차원의 변수들을 다루기 때문에 위의 식을 다변수(Multi-variable) 관점으로 다시 표현해줄 필요가 있습니다. 즉, 행렬로 표현하고자 합니다.
\[\mathbf{z} \sim \pi(\mathbf{z}), \mathbf{x} = f(\mathbf{z}), \mathbf{z} = f^{-1}(\mathbf{x})\\ p(\mathbf{x})=\pi(\mathbf{z})\Bigl|\text{det}\frac{d\mathbf{z}}{d\mathbf{x}}\Bigl| = \pi(f^{-1}(\mathbf{x}))\Bigl|\text{det}\frac{df^{-1}}{d\mathbf{x}}\Bigl|\]이제 변수 \(x,z\) 를 vector 표기로 바꾸면 \(\mathbf{x}, \mathbf{z}\) 로 나타내겠습니다. 그리고 아직 하나 남은 것이 있는데요 바로 미분입니다. 이제 우리는 행렬을 다루기 때문에 미분도 행렬의 미분으로 표현해야됩니다. 결론부터 말씀드리자면 행렬의 미분은 행렬입니다. 이런 도함수 행렬을 자코비안 행렬(Jacobian Matrix)이라고 하죠. 다음 절은 수식을 본격적으로 전개하기 앞서 자코비안 행렬과 행렬식에 대해 알아보도록 하겠습니다.
Jacobian Matrix and Determinant
행렬의 미분, 즉 도함수 행렬은 뭐다? 자코비안 행렬이다. 별거 없습니다. 딥러닝에서는 전부 행렬연산이기 때문에 기울기 계산 또한 행렬연산으로 진행됩니다. 따라서 딥러닝 공부하신 분들은 자코비안 자코비안 행렬 개념은 익숙하실 겁니다. 그러나 처음이신 분들도 있을테니 간단하게 소개를 해보고 넘어가겠습니다.
\[\mathbf J = \dfrac{d\mathbf y}{d\mathbf x} = \begin{bmatrix}\dfrac{\partial y_1}{\partial \mathbf x} \\\ \vdots \\\ \dfrac{\partial y_m}{\partial \mathbf x} \end{bmatrix} =\begin{bmatrix}\dfrac{\partial y_1}{\partial x_1} & \cdots & \dfrac{\partial y_1}{\partial x_n}\\\ \vdots & \ddots & \vdots\\\ \dfrac{\partial y_m}{\partial x_1} & \cdots & \dfrac{\partial y_m}{\partial x_n} \end{bmatrix}\]자코비안 행렬은 위와 같이 정의됩니다. 벡터 \(\mathbf{x},\mathbf{y}\)에 대한 일차 편미분(기호는 \(\partial\))을 행렬로 나타낸 것입니다. 즉, 우리가 \(n\) 차원 입력 벡터 \(\mathbf{x}\)를 \(m\) 차원 출력 벡터 \(\mathbf{y}\)로 매핑하는(\(\mathbf{y}:\mathbb{R}^n \mapsto \mathbb{R}^m\)) 함수가 주어지면 이 함수의 모든 1차 편미분 함수 행렬을 자코비안 행렬로 간단하게 표현할 수 있는 것입니다. 딥러닝에서 그래디언트 디센트를 할때는 기울기 값을 계산해야되는데 저렇게 자코비안 행렬로 기울기 값을 계산한답니다.
이번엔 행렬식(Determinant)를 설명드리겠습니다. 행렬식은 정방행렬(n x n matrix)에 스칼라를 대응하는 함수의 하나입니다. 즉, 행렬을 대표하는 하나의 스칼라로 계산한다는 것이죠.
행렬식은 다음과 같습니다.
\[\det M=\det \begin{pmatrix} M_{11} & M_{12} & \cdots & M_{1n} \\ M_{21} & M_{22} & \cdots & M_{2n} \\ \vdots & \vdots & & \vdots \\ M_{m1} & M_{m2} & \cdots & M_{mn} \\ \end{pmatrix}\]또는
\[|M|= \begin{vmatrix} M_{11} & M_{12} & \cdots & M_{1n} \\ M_{21} & M_{22} & \cdots & M_{2n} \\ \vdots & \vdots & & \vdots \\ M_{m1} & M_{m2} & \cdots & M_{mn} \\ \end{vmatrix}\]로 표기할 수 있습니다.
제가 행렬식은 아까 스칼라로 대응하는 함수라고 말씀드렸습니다. 따라서 다항식으로도 정의할 수 있는데 이 부분은 넘어가도록 할테니 궁금하신 분은 위키피디아에서 확인하시기 바랍니다. (사실 수식이 자꾸 깨집니다…)
이번엔 행렬식의 주요 성질을 적어보도록 하겠습니다. 향후에 연산과정을 간단하게 해주는데 많은 도움을 주니 참고하시면 좋을 것 같습니다.
- \(\det(1_{n\times n})=1\).
- \(\det(MN)=\det M\det N\).
- 행렬 \(M\)이 가역행렬(invertible matrix, 역행렬이 있는 행렬)인 경우, \(\text{det}M \neq 0\).
- 행렬 \(M\)이 가역행렬인 경우, \(\det M^{-1}=(\det M)^{-1}\).
- \(\det(M^\mathbf\top)=\det M\).
이렇게 자코비안 행렬과 행렬식을 알아보았고 이제 위에서 전개한 수식 중 \(\vert\text{det}\frac{df^{-1}}{d\mathbf{x}}\vert\)을 해결할 수 있게 되었습니다.
Normalizing Flow
지금까지 우리는 \(\mathbf{x}\) 에 대한 확률밀도함수 \(p(\mathbf{x})\)를 잠재변수라고 가정한 \(\mathbf{z}\)를 이용해 추정 할 수 있음을 확인했습니다. 하지만, 정말 좋은 \(p(\mathbf{x})\)를 추정한다는 것(density estimation)은 쉽지 않습니다. 실제 딥러닝 생성 모델들은 사후 확률 \(p(\mathbf{z}\vert\mathbf{x})\) 를 비교적 간단한 확률 분포로 가정하거나 근사시킵니다. 일반적으로 가우시안 분포가 사용됩니다. 실제 데이터 분포는 (i.e. \(p(\mathbf{x})\)) 는 굉장히 복잡하기 때문에 적어도 잠재 변수의 확률 분포가 단순해야지 딥러닝이 역전파 계산을 조금이라도 더 쉽게 할 수 있기 때문입니다.
이번 절에서 알아볼 Normalizing Flow (NF) 은 실제 데이터의 복잡한 확률 분포를 예측하는데 있어서 효과적인 방식 중 하나입니다. 아이디어는 단순합니다. 우리는 앞서 어떠한 확률 분포에 역변환 함수를 적용해서 새로운 확률 분포로 변환 할 수 있는 것을 확인했습니다. Normalizing Flow 는 단순한 확률 분포에서부터 일련의 역변환 함수를 적용하여 점차 복잡한 확률 분포로 변환해 나갑니다. 이런 일련의 변환과 변수 변환 이론을 통해 우리는 단순한 분포로부터 새로운 변수들을 반복해서 대체하고 결과적으로 목표하는 최종 변수의 확률 분포를 얻을 수 있게 됩니다.
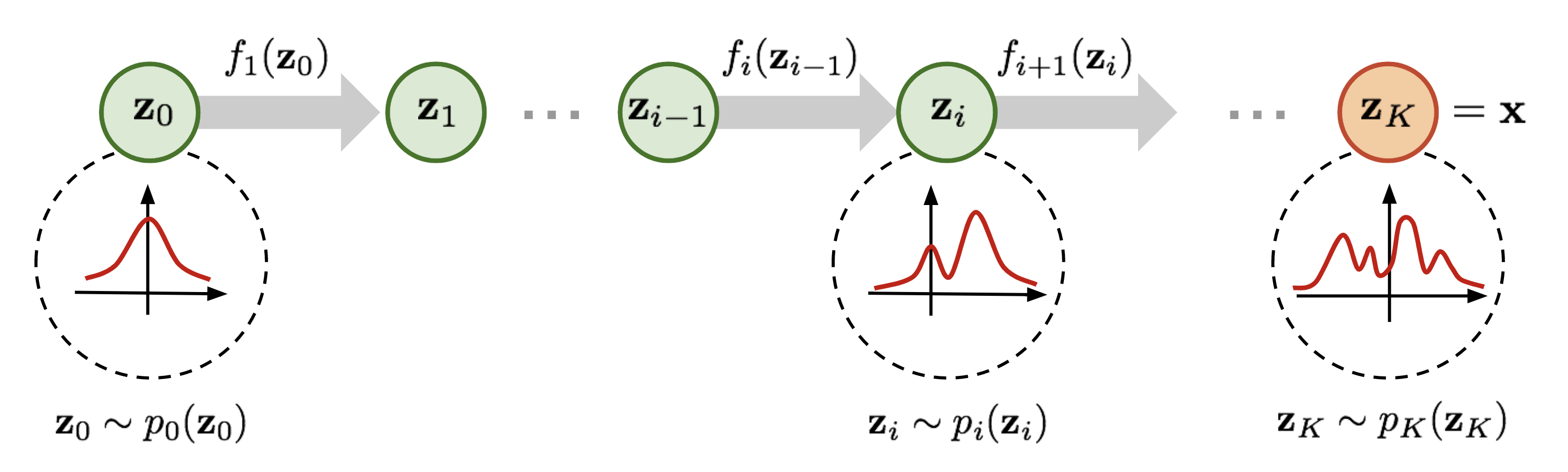
Fig. 2. Illustration of a normalizing flow model, transforming a simple distribution \(p_0(\mathbf{z}_0)\) to a complex one \(p_K(\mathbf{z}_K)\) step by step. (출처 - Lil’Log, Flow-based Deep Generative Models)
그림 2의 정의에 따르면 다음과 같이 나타납니다.
\[\mathbf{z}_{i-1} \sim p_{i-1}(\mathbf{z}_{i-1}) \\ \mathbf{z}_i = f_i(\mathbf{z}_{i-1})\text{, thus }\mathbf{z}_{i-1} = f_i^{-1}(\mathbf{z}_i) \\ p_i(\mathbf{z}_i) = p_{i-1}(f_i^{-1}(\mathbf{z}_i)) \left\vert \det\dfrac{d f_i^{-1}}{d \mathbf{z}_i} \right\vert\]이 수식 저희가 위에서 정리했던 수식과 동일한거 보이시나요? 달라진 점은 연속된 역변환을 나타내기 위해서 \(i\) 번째의 변수와 확률분포 그리고 역변환을 표시한 것 뿐입니다. 일단, 조금만 더 수식을 정리해보도록 하겠습니다.
\[\begin{aligned} p_i(\mathbf{z}_i) &= p_{i-1}(f_i^{-1}(\mathbf{z}_i)) \left\vert \det\dfrac{d f_i^{-1}}{d \mathbf{z}_i} \right\vert \\ &= p_{i-1}(\mathbf{z}_{i-1}) \left\vert \det \color{red}{\Big(\dfrac{d f_i}{d\mathbf{z}_{i-1}}\Big)^{-1}} \right\vert \\ &= p_{i-1}(\mathbf{z}_{i-1}) \color{red}{\left\vert \det \dfrac{d f_i}{d\mathbf{z}_{i-1}} \right\vert^{-1}} \\ \log p_i(\mathbf{z}_i) &= \log p_{i-1}(\mathbf{z}_{i-1}) - \log \left\vert \det \dfrac{d f_i}{d\mathbf{z}_{i-1}} \right\vert \end{aligned}\]일단 빨간색 글씨를 친 부분은 우리가 수식을 좀더 깔끔하게 정리하기 위해서 역함수 이론 (Inverse function theorem) 과 가역함수의 자코비안 (Jacobians of invertible function) 특성에 따라 전개했습니다.
역함수 이론에서, 만약 \(y = f(x)\) 와 \(x = f^{-1}(y)\) 가 있다면,
\[\dfrac{df^{-1}(y)}{dy} = \dfrac{dx}{dy} = (\dfrac{dy}{dx})^{-1} = (\dfrac{df(x)}{dx})^{-1}\]가 됩니다. 즉, 역함수의 미분과 함수의 미분은 inverse 관계라는 것이죠. 따라서 위에서도 우리는 역함수의 자코비안을 함수의 자코비안의 역으로 표현이 가능합니다.
가역함수의 자코비안 은 결국 가역행렬인 경우의 행렬식 특성들을 갖습니다.
\[\det(M^{-1}) = (\det(M))^{-1} \\ \det(M)\det(M^{-1}) = \det(M \cdot M^{-1}) = \det(I) = 1\]따라서 우리는 빨간색 부분을 좀 더 보기 좋게 정리할 수 있게 됩니다.
마지막으로 Log를 취한 것을 보실 수 있는데 약간의 팁을 드리자면, 확률 등의 수식에서 곱셈이 나올때 전체적으로 Log로 취해주면 대부분은 곱을 합으로 바꿀 수 있습니다. 그러면 연산이 더욱 쉬워집니다. 조금 더 이점들을 말해보자면, 연속된 곱이 등장한 경우 각각의 값들이 너무 작을 때 (1보다 작은 경우) 곱셈의 결과가 0에 가까워지기 때문에(underflow 현상 같이) 연산이 힘들어질 수 가 있습니다. 마지막 수식의 경우에도, Log를 씌워줌으로서 곱셈을 합으로 바꾸어 주었습니다. 즉, 이제 연속적인 역변환을 계산해도 곱셈을 유한합(Summation)으로 처리할 수 있게 되는거죠.
드디어 우리는 \(\mathbf{z}_0\) 의 확률분포에서부터 시작해 \(K\) 번의 역변환을 통해 \(\mathbf{x}\) 의 확률분포를 구하는 수식을 앞에서 배웠던 것들을 활용하여 정리할 수 있게 되었습니다.
\[\begin{aligned} \mathbf{x} = \mathbf{z}_K &= f_K \circ f_{K-1} \circ \dots \circ f_1 (\mathbf{z}_0) \\ \log p(\mathbf{x}) = \log \pi_K(\mathbf{z}_K) &= \log \pi_{K-1}(\mathbf{z}_{K-1}) - \log\left\vert\det\dfrac{d f_K}{d \mathbf{z}_{K-1}}\right\vert \\ &= \log \pi_{K-2}(\mathbf{z}_{K-2}) - \log\left\vert\det\dfrac{d f_{K-1}}{d\mathbf{z}_{K-2}}\right\vert - \log\left\vert\det\dfrac{d f_K}{d\mathbf{z}_{K-1}}\right\vert \\ &= \dots \\ &= \log \pi_0(\mathbf{z}_0) - \sum_{i=1}^K \log\left\vert\det\dfrac{d f_i}{d\mathbf{z}_{i-1}}\right\vert \end{aligned}\]딥러닝 모델이 학습할 수 있게 해주려면 우리는 항상 적절한 학습 criterion을 제공해야됩니다. 분류 학습에는 주로 Cross-Entropy 가 사용되는 것처럼요. 다행인 것은 우리가 NF 를 이용해 비교적 쉽게 \(\log{p(\mathbf{x})}\) 를 정의할 수 있었습니다. 그럼 남은 것은 우리가 가지고 있는 학습 데이터셋 \(\mathcal{D}\) 에 대해 간단하게 Negative Log-Likelihood (NLL) 을 만들어서 생성 모델에게 학습 criterion 으로 넘겨주면 끝납니다.
\[\mathcal{L}(\mathcal{D}) = - \frac{1}{\vert\mathcal{D}\vert}\sum_{\mathbf{x} \in \mathcal{D}} \log p(\mathbf{x})\]이것이 바로 Normalizing Flow 방식입니다. 간단하죠? 그 대신, 해당 방정식의 계산이 가능하게 하려면 두 가지 조건을 충족해야됩니다.
- 함수 \(f\) 는 가역적이여야 한다.
- \(f\) 에 대한 자코비안 행렬식은 계산하기 쉬워야 된다.
이런 조건들이 만족하지 않으면 아무리 NF 가 강력하더라도 딥러닝 모델이 학습하기가 쉽지 않습니다. 그런데 문제는, 위의 조건을 만족하도록 하는 것부터가 쉽지 않다는 것이죠. 그래서 다음 시간에는 NF 기반의 생성 모델들은 이런 어려움을 어떤식으로 극복하였는지를 논문 리뷰와 함께 풀어나가보도록 하겠습니다.
댓글남기기