About me
I am a second-year Ph.D. candidate at KAIST advised by
Professor Joon Son Chung,
and I earned my M.S. from KAIST.
My research focuses on audio representation learning and its connection to
Audio-LLM systems. I am interested in how audio representations can be made
robust under real-world variability, transformed across representation spaces, and
exposed to language-model interfaces.
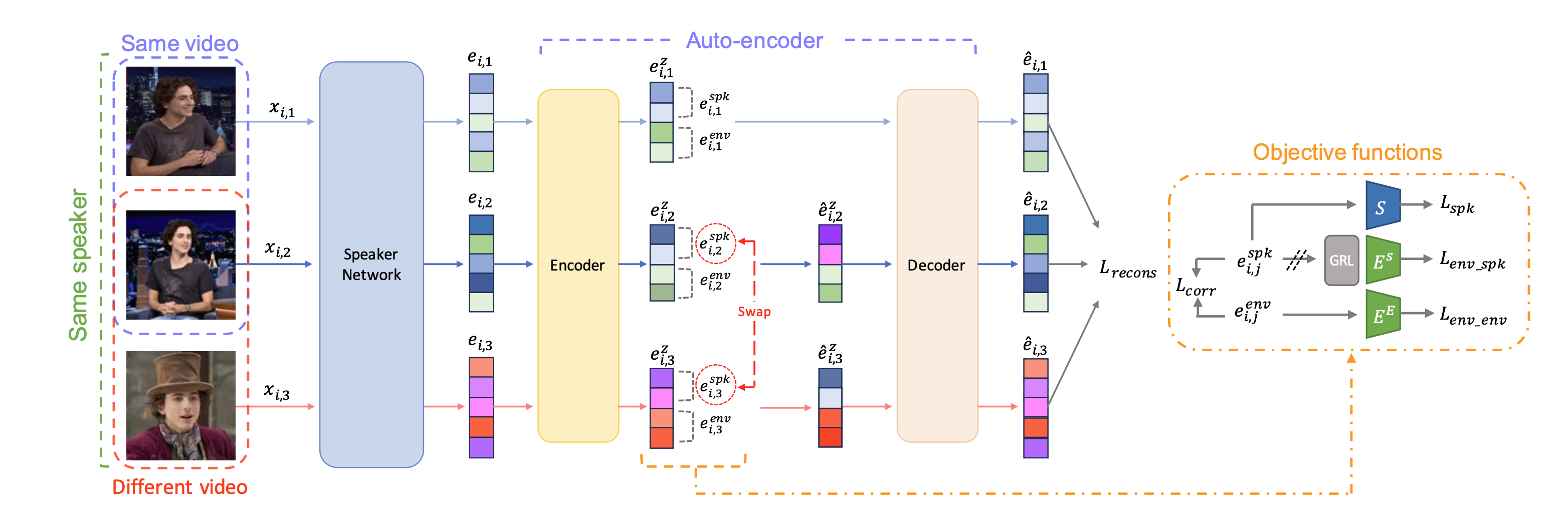
My work started from robust speech and speaker representation learning, where audio
models must preserve task-relevant information while handling language, environment,
session, channel, and recording mismatch. Building on this foundation, I have recently
explored generative representation alignment: using diffusion-based methods to
enhancement or transform audio representations at the latent level. In this direction,
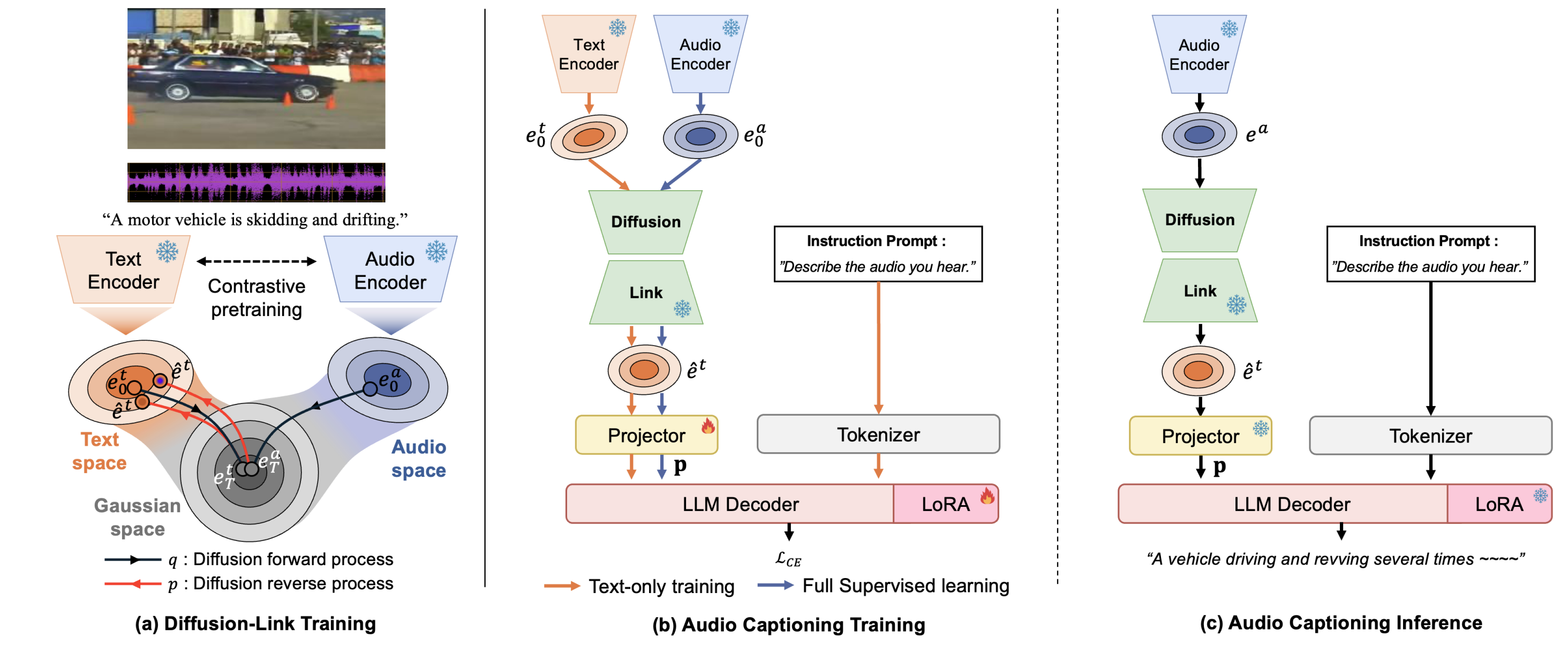
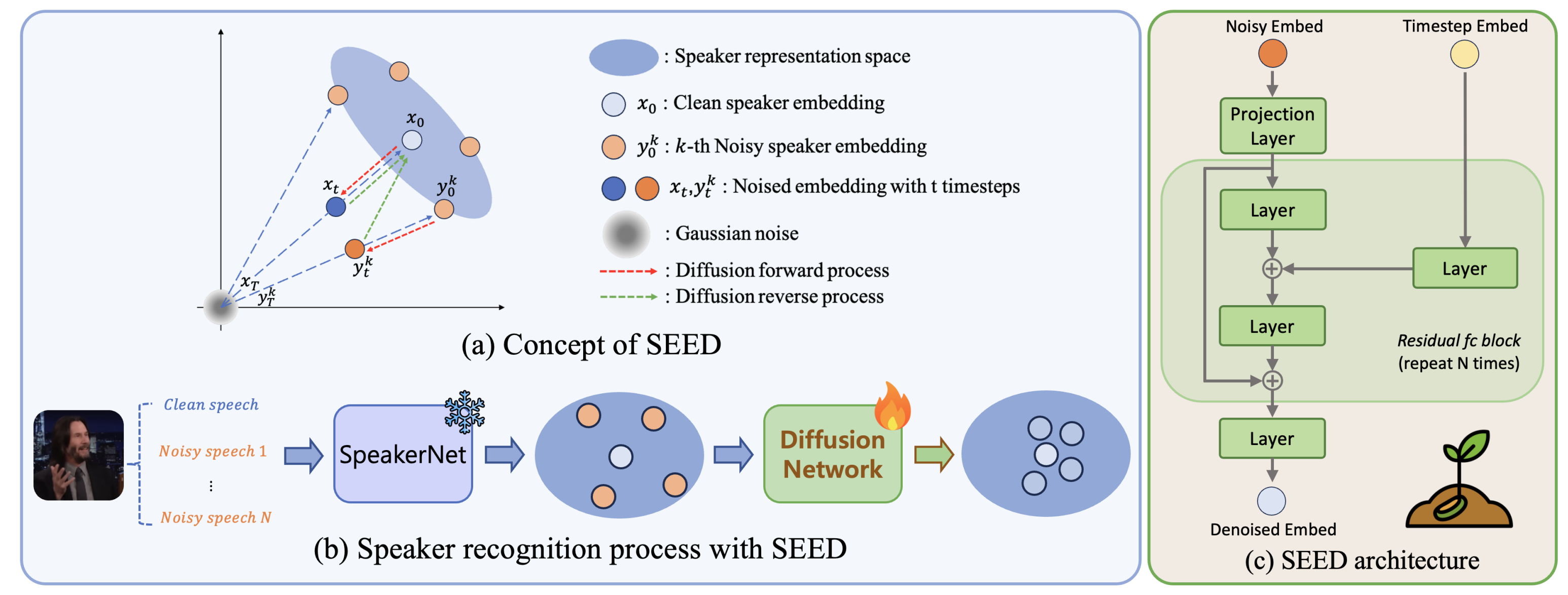
SEED studies speaker embedding enhancement, while Diffusion-Link bridges
the audio-text modality gap by transporting audio representations toward
text-aligned spaces for Audio-LLMs and multimodal LLMs.
More recently, I have been interested in specialized Audio-LLM systems.
As voice becomes a primary interface for robots, smart glasses, wearables, vehicles,
and other physical AI systems, Audio-LLMs will need capabilities beyond ASR.
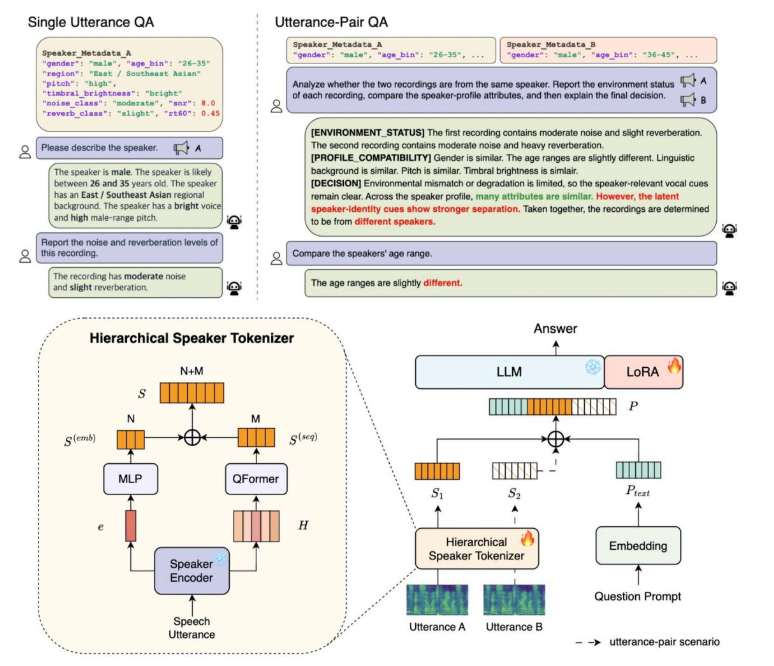
My recent work SpeakerLLM explores this direction by enabling an Audio-LLM to
understand speaker identity, recording conditions, utterance-pair relations, and
verification reasoning through a natural-language interface.
Going forward, I am interested in building audio-native intelligence for
voice-first systems, including speaker-aware Audio-LLMs, audio-text representation
alignment, and full-duplex speech-to-speech agents. My long-term goal is to
build Audio-LLM systems that use audio not only as transcribed text, but as rich
evidence for reasoning, personalization, and real-time interaction.
Experience
Deep Learning Research Intern, NAVER Clova Speech (now NAVER CLOUD), S. Korea
Sep. 2019 - Feb. 2020
Deep Learning Research Intern, NAVER Clova Speech (now NAVER CLOUD), S. Korea
Mar. 2021 - Sep. 2021
Education
Ph.D. in School of Electrical Engineering, KAIST
Sept. 2024 - Present
Advisor: Joon Son Chung (Multimodal AI Lab)
M.S. in School of Electrical Engineering, KAIST
Aug. 2022 - Aug. 2024
Advisor: Joon Son Chung (Multimodal AI Lab)
B.S. in Computer Science, Hankuk University of Foreign Studies (HUFS)
Mar. 2015 - Aug. 2022
Selected Awards
2024
- NIST 2024 Speaker Recognition Evaluation – 1st Place (Audio Track) / 4th Place
(Audio‑Visual Track) – Collaboration with Microsoft, KAIST MMAI Lab, PolyU, NUS and UEF